
【VPC内リージョンサービス】
Aurora は、AWS が提供するフルマネージド型データベースサービスである RDS(Relational Database Service) の一部として提供される、AWS 独自設計の MySQL / PostgreSQL 互換のRDBです。
RDS と同様に、バックアップ、フェイルオーバー、スケーリング、パッチ適用、監視などの運用管理を自動化し、運用負荷を大幅に軽減します。
Aurora は、クラスタ構造を採用しており、1つのクラスター内にプライマリインスタンスと複数のRead Replica(リードレプリカ)を持つことで、高い可用性とスケーラビリティを実現します。
Auroraのストレージは6-way replicated storage(6重複写ストレージ)によって構成され、3つのAZ(Availability Zone)に分散配置されます。これにより、自動自己修復機能を備え、障害に強く、秒間数百万IOPS級の高性能を発揮します。また、Storage Auto-Scaling(ストレージ自動拡張)機能により、データ量の増加に応じてストレージが自動的に拡張され、最大128TBまでスケールします。
Aurora Serverless v2 に対応しており、ワークロードの変化に応じてコンピューティングキャパシティがリアルタイムにスケーリングします。これにより、負荷変動の大きいアプリケーションでも効率的かつコスト最適に運用できます。さらに、I/O-Optimized(I/O最適化) モードを利用することで、ストレージI/Oのレイテンシを最小化し、安定した高スループットを実現します。
Global Database 機能により、複数のAWSリージョン間で非同期レプリケーションを行い、グローバル規模での読み取り性能向上やDR(Disaster Recovery:災害復旧)対策を実現します。
Multi-Master構成を利用することで、複数のWriterインスタンスによる同時書き込みが可能になり、高い可用性と可用性を両立します。
AuroraはRead Replicaを最大15個まで作成でき、読み取りトラフィックを効率的に分散できます。障害発生時には自動フェイルオーバーが行われ、サービスを中断することなく継続運用できます。さらに、Custom Endpoints機能を使うことで、特定のRead Replica群に対して個別の接続エンドポイントを設定し、ワークロードに応じた柔軟な負荷分散が可能です。
Backtrack(バックトラック)機能では、数秒~数時間前の任意時点に即座にロールバックでき、誤操作や検証作業時に便利です。
Fast Cloning(クローン機能)により、コピーオンライト技術を使って大規模データベースを瞬時に複製できるため、開発・検証環境の構築を迅速に行えます。
Parallel Query(並列クエリ)機能では、クエリ処理をストレージ層で並列化し、大規模データ分析やバッチ処理を高速に実行できます。
重要用語
ユースケース
| 高可用・高性能な基幹DB | Amazon Aurora MySQL/PostgreSQL互換エンジンを利用し、自動ストレージ拡張と高速なリカバリを備えた基幹システム用データベースを構築する。 |
| サーバーレスDBによるスパイク対応 | Aurora Serverlessを使い、アクセスが少ない時間帯は自動的にリソースを縮小し、ピーク時だけスケールアウトするコスト最適なDB基盤を実現する。 |
| マイクロサービスごとの分離DB | マイクロサービスごとに小さなAuroraクラスターを用意し、スキーマや負荷を分離した構成で独立性とスケーラビリティを高める。 |
ベストプラクティス
| リーダー/リーダーエンドポイントの活用 | 読み取りトラフィックをリーダーにオフロードしスケールアウトする。 |
| バックトラックやGlobal Database | 誤更新対策やグローバル展開にAurora固有機能を利用する。 |
| Auto Scalingとサーバーレス検討 | 負荷変動が大きい場合はリーダーのオートスケーリングやAurora Serverlessを検討する。 |
高可用性・バックアップ・リトライ
| 高可用性・バックアップ・リトライ設計のポイント |
|---|
| 【デフォルト】AWS内部で冗長化 ・ストレージの6重化(データは自動的に3つのAZにまたがって6つのコピーが作成される) ・データブロックの継続的スキャンと自動修復(ストレージ層で破損データを自動検出) ・Write Ahead Log(トランザクションログが複数AZに自動分散) ・ストレージの自動スケーリング(10GBずつ自動拡張 最大128TB) |
| 【リードレプリカ】の作成(最大5台、15台) |
| 【クラスタのマルチAZ構成】(ストレージはデフォルトで6重化) |
| 【データベースプロキシ】の利用(アプリケーションの接続要求を RDS Proxy がまとめてプール) |
| 【グローバルデータベース】(ディザスタリカバリ要件がある場合) |
| 【自動バックアップ】バックアップ保持期間 1~35 日 デフォルト 1 日 クラスタボリュームを継続的に S3 にバックアップ PITR:継続的バックアップ+トランザクションログにより、保持期間内の任意時点に復元可能 |
| 【手動スナップショット】任意のタイミングで取得可能 保持期限は無制限(ユーザーが削除するまで保持) クラスタボリューム全体を S3 ベースの永続ストレージに保存 スナップショットからいつでもクラスタを復元可能(スナップショット時点での復元) |
セキュリティ
| 関連サービス | 設定内容 |
|---|---|
| Subnet(公開リソースと内部リソースの分離) | 【DBサーバ】 Privateの専用SubnetでマルチAZ構成 |
| SG(リソース単位のアクセス制御) | 【DBサーバ】 インバウンド:3306(MySQL) 5432(PostgreSQL) アウトバウンド:すべて許可 |
| KMS(データの暗号化と鍵の安全管理) | 【 AWS管理キーによる暗号化を実施】 独自KMSキーを使うことを推奨(鍵操作、監査) |
| Secrets Manager(機密情報の安全管理) | シークレット(秘密情報)の作成が推奨 DB認証情報 |
| SSM Parameter Store(設定情報の一元管理) | - |
| CloudTrail(操作履歴の記録・監査・追跡) | 【自動記録】 作成・更新・削除・設定変更は自動記録される。(コントロールプレーンAPI) データ操作は追跡できない(データプレーンAPI) |
| Config(リソースの構成状態・設定変更を記録) | 【Configが有効な場合】 DBクラスタ/インスタンス設定変更履歴・暗号化/バックアップ/パブリックアクセス準拠評価 |
| GuardDuty(脅威を自動検出) | 【GuardDutyが有効な場合】 RDS同様、ネットワーク通信とAPI異常検知 |
ログ・監視
| ログ出力先 | ログの種類 |
|---|---|
| CloudWatch Logs | データベースログ |
標準メトリクス
| メトリクス名 | 説明 |
|---|---|
| AuroraBinlogReplicaLag | Auroraバイナリログレプリカ遅延 |
| AuroraReplicaLag | Auroraレプリカ遅延 |
| BufferCacheHitRatio | バッファキャッシュヒット率 |
| RollbackSegmentHistoryListLength | ロールバックセグメント履歴長 |
| AuroraVolumeBytesLeftTotal | Aurora残容量 |
| EngineUptime | エンジン稼働時間 |
制限値(固定値/ハードリミット/ソフトリミット)
| 固定値 | 制限値 |
|---|---|
| スナップショット保持期間 | 1-35日 |
| データベース接続数 | インスタンスタイプに依存 |
| ハードリミット | 制限値 |
|---|---|
| 最大ストレージ | 128 TiB |
| リードレプリカ数 | 15 |
| バックトラック期間 | 最大72時間 |
| ソフトリミット | 制限値 |
|---|---|
| クラスターあたりのDBインスタンス数 | 15 |
| クロスリージョンスナップショット共有先 | 20アカウント |
AWS CLIのサンプルコード
SG を作成する(VPC ID 指定)
aws ec2 create-security-group \
--group-name sg-xxxxxxxx \
--vpc-id vpc-xxxxxxxxx \
--tag-specifications 'ResourceType=security-group,Tags=[{Key=Name,Value=sg-xxxxxxxx}]'SG ID を表示する
aws ec2 describe-security-groupsインバウンドルールを追加する(SG ID 指定)
aws ec2 authorize-security-group-ingress \
--group-id sg-xxxxxxxxx \
--protocol tcp \
--port 3306 \
--cidr 0.0.0.0/0SG を削除する(SG ID 指定)
aws ec2 delete-security-group \
--group-id sg-xxxxxxxxx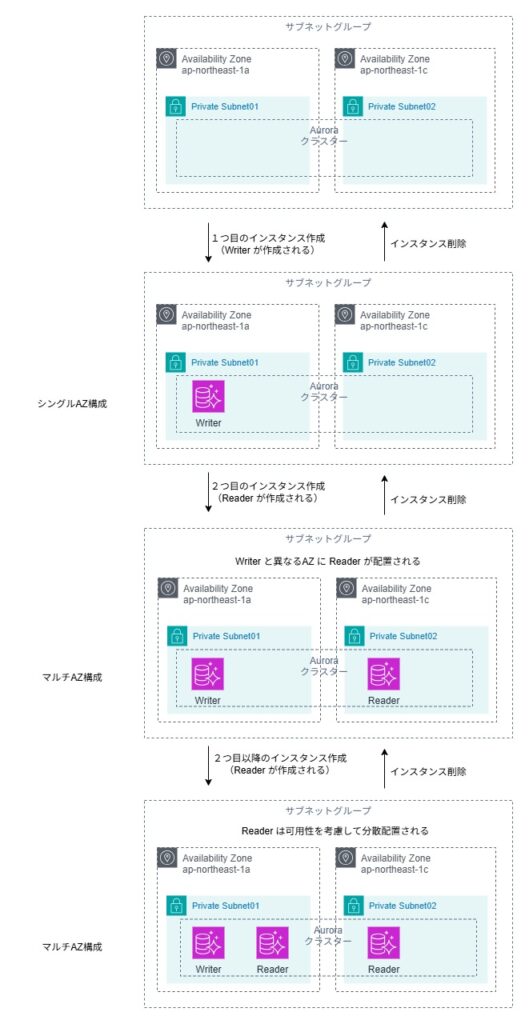
サブネットグループを作成する
aws rds create-db-subnet-group \
--db-subnet-group-name my-db-subnet-group \
--db-subnet-group-description "Aurora Subnet Group" \
--subnet-ids subnet-xxxxx subnet-yyyyyサブネットグループを表示する
aws rds describe-db-subnet-groupsサブネットグループを削除する(サブネットグループ名 指定)
aws rds delete-db-subnet-group \
--db-subnet-group-name my-db-subnet-groupAurora クラスタを作成する(SG ID、サブネットグループ名 指定)
aws rds create-db-cluster \
--db-cluster-identifier my-aurora-cluster \
--engine aurora-mysql \
--engine-version 8.0.mysql_aurora.3.04.0 \
--master-username admin \
--master-user-password MyPassword123! \
--db-subnet-group-name my-db-subnet-group \
--vpc-security-group-ids sg-xxxxxAurora クラスタを表示する
aws rds describe-db-clustersAurora クラスタを削除する(クラスタID 指定)
aws rds delete-db-cluster \
--db-cluster-identifier my-aurora-cluster \
--skip-final-snapshotAuroraインスタンスを作成する(クラスタID 指定)
1個目のインスタンス ・・・ ライター(プライマリ)
2個目以降のインスタンス ・・・ リーダー(レプリカ)
aws rds create-db-instance \
--db-instance-identifier my-aurora-instance-1 \
--db-instance-class db.t3.medium \
--engine aurora-mysql \
--db-cluster-identifier my-aurora-clusterAuroraインスタンスを表示する
aws rds describe-db-instancesAuroraインスタンスを削除する(インスタンス ID 指定)
aws rds delete-db-instance \
--db-instance-identifier my-aurora-instance-1 \
--skip-final-snapshotAurora クラスタを起動する(クラスタ ID 指定)
aws rds start-db-cluster \
--db-cluster-identifier my-aurora-clusterAurora クラスタを停止する(クラスタ ID 指定)
aws rds stop-db-cluster \
--db-cluster-identifier my-aurora-clusterスナップショットを作成する(クラスタ ID 指定)
aws rds create-db-cluster-snapshot \
--db-cluster-identifier my-aurora-cluster \
--db-cluster-snapshot-identifier my-snapshot-20241205スナップショットを表示する(クラスタ ID 指定)
aws rds describe-db-cluster-snapshots \
--db-cluster-identifier my-aurora-clusterスナップショットを削除する(スナップショット ID 指定)
aws rds delete-db-cluster-snapshot \
--db-cluster-snapshot-identifier my-snapshot-20241205スナップショットからクラスターを復元する(クラスタ ID 指定、スナップショット ID指定)
aws rds restore-db-cluster-from-snapshot \
--db-cluster-identifier my-restored-cluster \
--snapshot-identifier my-snapshot-20241205 \
--engine aurora-mysqlフェールオーバーを実行する(クラスタID、昇格させるインスタンスID 指定)
aws rds failover-db-cluster \
--db-cluster-identifier my-aurora-cluster \
--target-db-instance-identifier my-aurora-instance-2CloudFormationのサンプルコード
Terraformのサンプルコード
料金計算
| 課金項目 | 説明 |
|---|---|
| インスタンス時間 | データベースインスタンスの稼働時間 |
| ストレージ容量 | 使用したストレージ容量(10GB単位で自動拡張) |
| I/Oリクエスト | 100万I/Oリクエスト単位 |
| バックアップストレージ | 保持期間を超えるバックアップの容量 |
| データ転送 | インターネットへのデータ転送量 |
| グローバルデータベース | リージョン間のレプリケーション |
| Serverless | ACU(Aurora Capacity Units)の使用量 |