
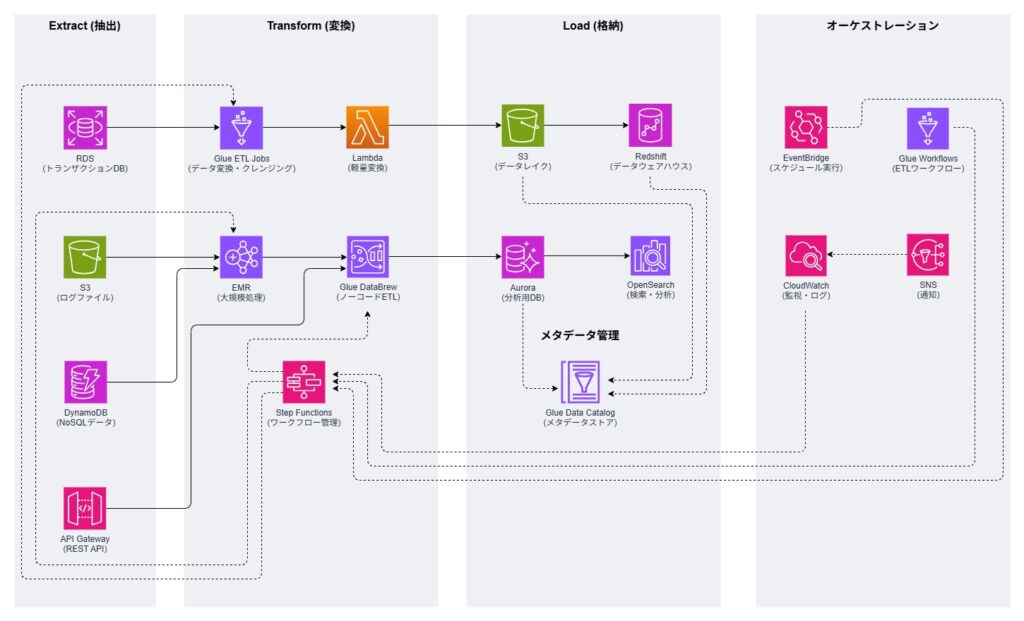
| 全体構成 | データの抽出・変換・格納処理の全体フローを4つのセクションに分けて設計されたETL処理です |
| Extract (抽出) | RDS (トランザクションDB) DynamoDB (NoSQLデータ) S3 (ログファイル) API Gateway (REST API) |
| Transform (変換) | Lambda (軽量変換) Glue ETL Jobs (データ変換・クレンジング) Glue DataBrew (ノーコードETL) EMR (大規模処理) Step Functions (ワークフロー管理) |
| Load (格納) | S3 (データレイク) Aurora (分析用DB) Redshift (データウェアハウス) OpenSearch (検索・分析) |
| メタデータ管理 | Glue Data Catalog:(メタデータストア) |
| オーケストレーション | EventBridge (スケジュール実行) Glue Workflows (ETLワークフロー) CloudWatch (監視・ログ) SNS (通知) |
表1.全体構成(ETL処理)
| 処理規模に応じた変換 | Lambda(軽量) Glue(中規模) EMR(大規模) |
| 目的別データストア | Aurora(リアルタイム分析) Redshift(大規模分析) OpenSearch(検索) S3(データレイク) |
| メタデータ管理 | テーブル定義・スキーマ・パーティション情報などのメタデータを一元管理 |